
The Power of ADR
Agentic coding tools ask software engineers to take a step back from pure software development skills and focus more on architectural decisions, organization, and hierarchy of a project.
A project from scratch or an existing, long-running codebase doesn’t have the same requirements or the same complexity. Still, the need to have a clear understanding of the architecture becomes one of the primary skills required in software engineering in our era of Agile development.
Very quickly, to streamline this architectural need, a practice started to be democratically used on an AI-coded app: ADR, for Architectural Decision Record.
This concept has been invented and popularized by Michael Nygard.
But what is an ADR, and why has it become a natural answer to the need pushed by the Agentic tools? Let’s see.
What is an Architectural Decision Record
An ADR, for Architectural Decision Record, is a document that relates to the decision on an architectural principle. Let’s take an example. A real-life example.
I’m working at Teads, a company building a global platform for advertising. A big chunk of the advertising business focuses on helping brands deliver clicks, visits, and even lower-funnel outcomes like purchases. This is what we call “Performance Advertising”. Performance because we are truly converting the spending on advertising into a concrete impact on your website.
To achieve that, advertisers use dedicated services/pieces of code to inform our platform when a noticeable event happens. On our side, by being noticed, and because we are also responsible for the ad played on the publisher website, we can try to attribute this event to an ad displayed by our platform.
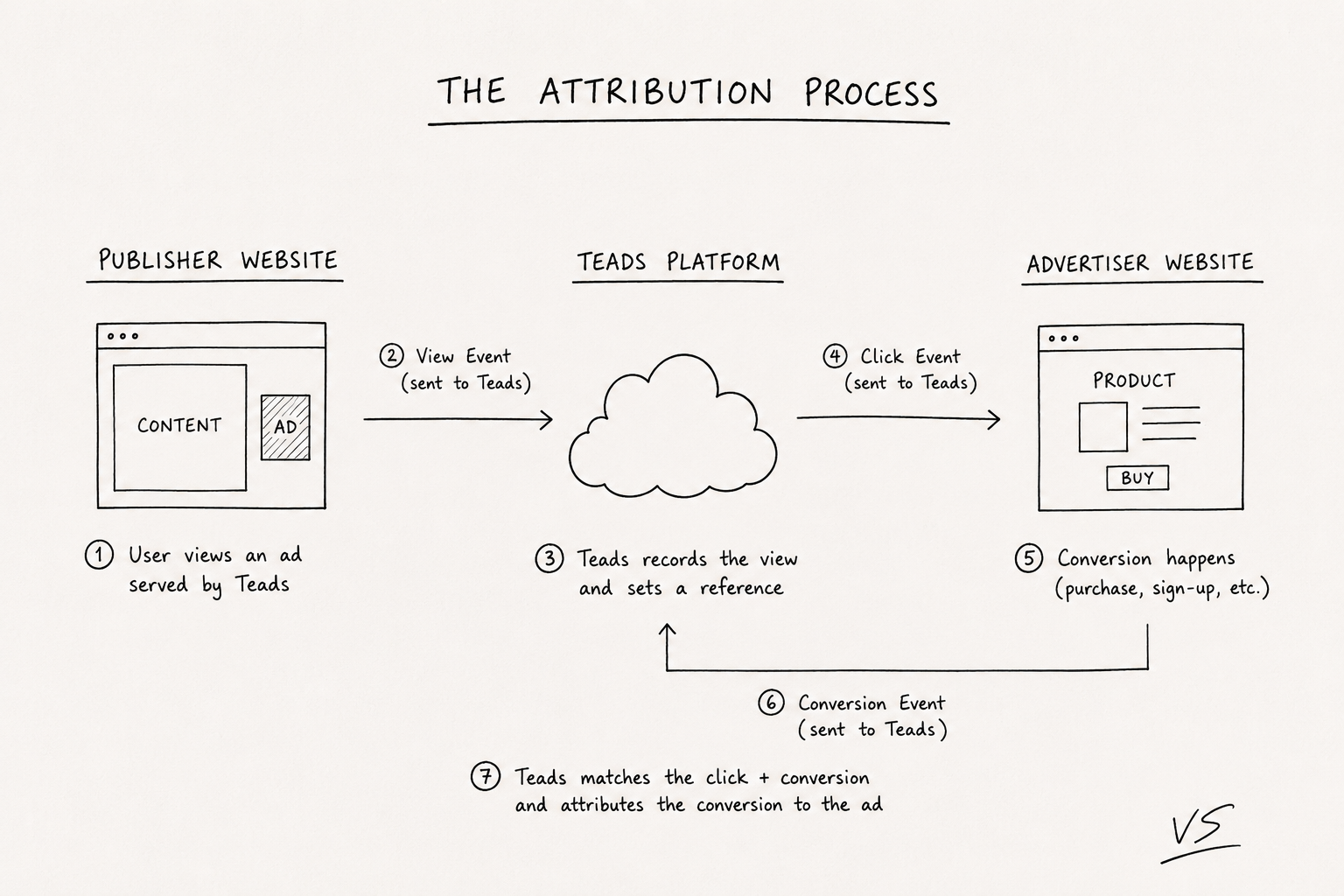
To handle this attribution process, we have a “Performance Attribution Pipeline”. This is a sequence of multiple workflows using a DAG-like mechanism that associates events caught on advertiser websites with events done on publisher websites.
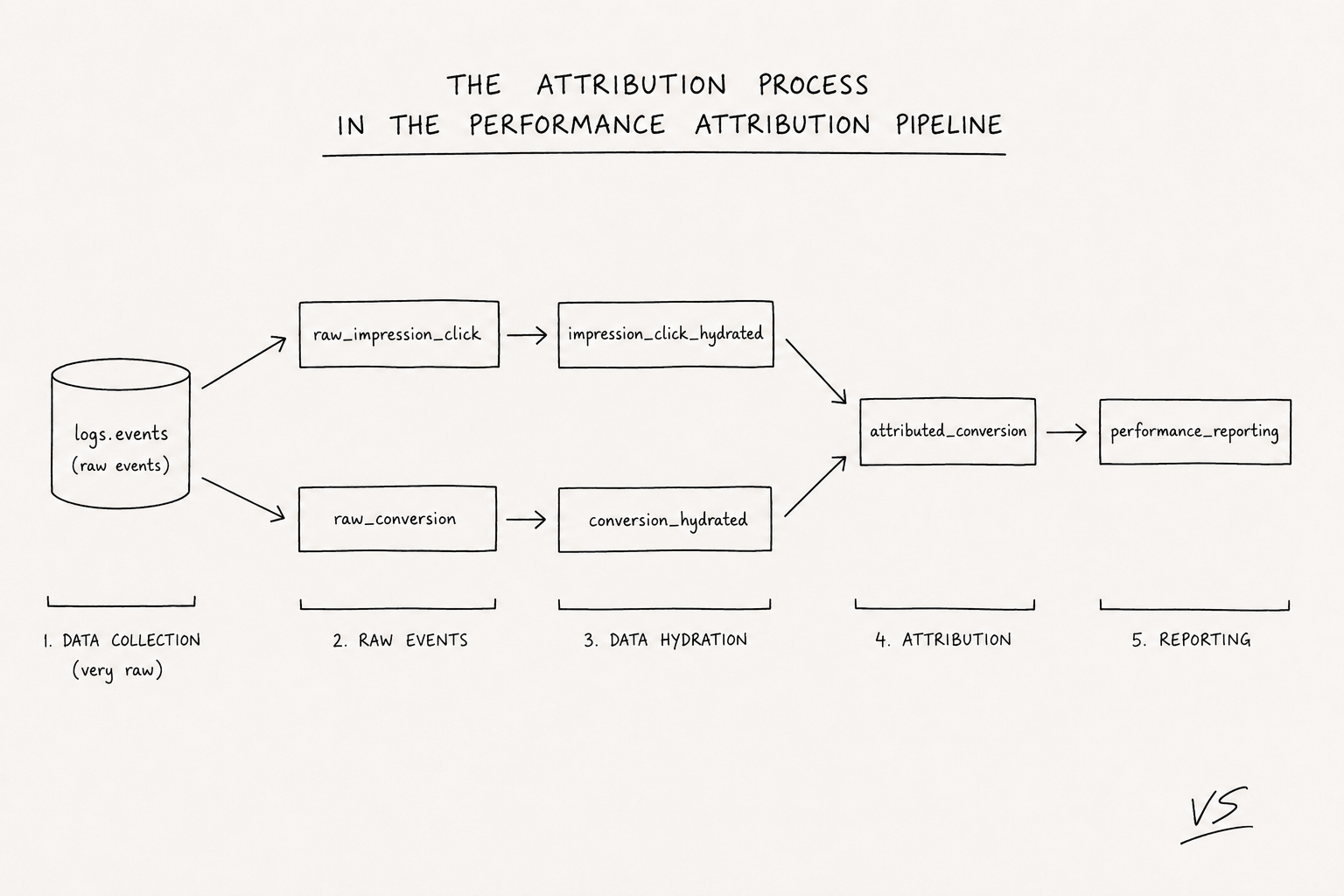
This pipeline has one main goal: associate a “conversion” event with a “click” or “impression event”. If the conversion is associated with an impression, we call that a post-view conversion; otherwise, it’s a post-click conversion.
This is critical for the business to distinguish them. Some clients are paying more attention to post-click than post-view.
However, today, our pipeline doesn’t compute “visit” event as a standard conversion. A visit is associated with a conversion generated automatically, but the whole pipeline stops to split them and just aggregates “Visit” as it is.
The reason behind? I don’t know… Unfortunately, there is no ADR for that 😅.
I had two assumptions:
- Our pipeline was designed first for visits because Teads came from the branding landscape and moved to conversion later
- We were counting visits only post-click with a standard and fixed lookback window of one day historically.
As there is no ADR, and because the original builders of this pipeline are no longer in the company, I can’t know for sure 🤷♂️
But a few years ago, Teads started its journey on the CTV landscape. We introduced the CTV Performance offering, which allowed us to monitor how a campaign on connected TV generated visits on websites via mobile. It’s a cross-device performance offering, and naturally, no click can happen. We started to allow counting visits using “impression”, but only if the supply was identified as CTV.
This year, one of our ambitions is to allow our clients to run CTV and web performance objectives in one campaign. The impact? A mix of visits that is either post-click or post-view. Of course, aggregating them isn’t viable due to the business requirement mentioned above, so we need to count them like we count conversions: post-click and post-view visits.
We started to evaluate multiple options, from the most natural to the simplest one:
- Consider a visit as a traditional conversion
- Add a new post-click / post-view visit distinction on visit metrics and aggregate both for the standard
After investigation, evaluation of complexity, time required, and time constraints, we came to a decision. The decision we took isn’t the purpose of this document. However, explaining the different solutions, a summary of each of them, pros and cons, and the rationale of why to choose A or B is important to being able to make better decisions later. All of this is what we call an ADR.
We have two examples in a row:
- We have the explanation of what is an ADR, what it would contain, and why it would be useful
- We have a counterexample of a decision made without an ADR that is likely damaging for the team or the company.
One important thing about ADR is that they should be concise. Not too concise, it’s not a social network post, but not too long either, it’s not an RFC 😅 The ADR must help future readers to understand the problem, the decision taken, and why. The detail of the implementation or the deeper understanding of this solution isn’t the purpose of an ADR; this is not a technical design documentation.
What isn’t an ADR?
First, an ADR must be small. Not too small to be useless, but small enough not to be lazy to read it. (It’s less and less true as it’s mostly an Agentic tool that will read them, but… still a good practice IMHO)
Based on that, an ADR is not design documentation. A Design Documentation describes the whole design for a feature or a project. An ADR can track one or multiple decisions recorded and linked to a Design Documentation, but we must not use an ADR as design documentation.
Why? Simply, remind the purpose of an ADR:
An ADR is a document that relates to the decision on an architectural principle.
The ADR goal is first and foremost to keep track of a decision record. It must describe the decision and the rationale behind this decision. It must hold the technical detail required to understand the context and the decision. But it’s a document that must be used to understand WHY we took such a decision, not all the details of the architecture of a project linked to this decision.
Secondly, an ADR isn’t a product specification. It seems obvious, but it’s mostly for an engineering/technical purpose. The product requirement can be explained in the context to better understand the full picture. But an ADR isn’t meant to describe what a product or feature must do.
Why? I’m mostly in favor of removing the barrier between product and engineering. I’m qualifying myself as a Product Engineering Leader because I don’t believe in pure engineering leadership, especially in a solution/feature team driven by a business objective. But the human aspect and the document is different. Keeping documents separated to speak about product and engineering is better. Not only for that, but the main reason is that they do not have the same estimated life, nor the same expectancy.
Finally, an ADR is not a technical specification. A technical specification describes HOW something is implemented: the specific APIs, data schemas, algorithms, protocols. An ADR is the layer above that. It explains WHY a decision was made, what tradeoffs were considered, and what constraints drove the choice. The implementation details live elsewhere. The reasoning lives in the ADR.
This distinction matters more than it sounds. If you start adding full API contracts or sequence diagrams to an ADR, it becomes a design doc. If you start describing user stories and acceptance criteria, it becomes a product spec. The ADR is the connective tissue between the two: the reasoning thread that explains why the architecture looks the way it does.
The good level of depth
Michael Nygard’s original definition proposed five fields: a title, a context, a decision, a status, and the consequences. That’s a solid base. Personally, I add two more. The date - which feels obvious but gets skipped more often than you’d think. And the rejected alternatives - which Nygard leaves implicit in the context or decision sections, but I prefer to make explicit. That’s the part that ages best.
The rule of thumb I use: an ADR should be readable in under five minutes. If it takes longer, it’s becoming something else.
Concretely, good depth means the context is enough for someone who just joined the team to understand why this decision even existed. Not the full history of the codebase, just what triggered the need for a decision in the first place.
The alternatives must be listed, at least briefly. Even one line per rejected option, with the reason why it was rejected. This is the part that gets skipped most often, and it’s the most valuable one in the long run.
The decision itself needs to be explicit. Not “we agreed to go with option A”. More like: we chose X because of the Y constraint and the Z tradeoff we were willing to accept.
The consequences should be honest too. A good ADR acknowledges the downside of the choice. No decision is perfect, and hiding the tradeoffs is what makes you regret not writing it properly three years later.
What you want to avoid is the opposite extreme: a three-page document with sequence diagrams, data models, and full API contracts. That’s a design doc. An ADR is the rationale layer on top of a design, not the design itself.
A quick sanity check I apply: could someone new to the team read this ADR and understand why we made this call, without asking anyone? If yes, the depth is right. If no, something is missing. If it takes more than five minutes to read, something is too much.
Why is it good in the AI era?
It’s kind of ironic that one of the first things the Agentic coding community started recommending was to write ADRs. Because it’s one of the oldest documentation practices in software engineering.
But there’s a very good reason for that.
LLMs are surprisingly good at extracting the structure of a codebase. Ask Claude Code or Cursor to describe the architecture of a project you just cloned, and the result will often impress you. They can infer patterns, dependencies, module responsibilities, and things that take a human dev hours to map.
What they have a hard time doing is inferring the why:
- Why was this service split from that one?
- Why is this queue here instead of a direct API call?
- Why are we not using the standard library for this?
The code doesn’t tell you everything. The git history doesn’t always tell you that. ADR does.
And here’s where it gets interesting with AI-assisted development: a lot of architectural decisions are now being made by or with an AI. You ask your coding agent to scaffold a new service, and it makes ten micro-decisions along the way, and none of them are recorded anywhere. Next week, you or the AI might make a contradictory decision in another part of the codebase, and no one will know.
An ADR forces you to pause, validate the AI’s reasoning, and put your name on it. Not just “the AI did this” but “we reviewed this, we agreed, and here’s why”. That’s a fundamentally different ownership model.
There’s something subtle here worth noting: ask an AI to make the same architectural decision twice, and it might take two different paths. Both can be valid - it’s probabilistic by nature. What matters isn’t recording what the AI chose, it’s recording the reflection you went through to agree or disagree with that choice. The value is in your reasoning, not in the AI’s output.
There’s also a more practical benefit: a well-written ADR is one of the best things you can put in context when starting a new session with your coding agent. It gives the AI a compact, high-signal description of constraints and rationale that would otherwise take it multiple code reads to approximate, and it would still get it wrong.
And when you’re later tempted to go in a new direction that would break an existing decision, the ADR is what tells you whether that change is justified or just drift. The why and the how you arrived at the original decision can be what gives you the confidence to either hold the line or make a new call - and write a new ADR for it.
Think of ADRs as the long-term memory that LLMs don’t have. You write them once, and they compound in value over time.
ADR has always been the answer
As mentioned at the beginning, ADR isn’t a new concept; it has existed for a while. But reusing them seems obvious for AI, where a lot of people forget about this.
I tried to introduce them three times in my career, and it was always a good idea, but very hard to sustain. With a stable team, the knowledge lives in people’s heads; it’s informal, but it works well enough. The ADR discipline never felt worth the friction when you could just ask the person who made the call. But now, with an agentic coding tool, team stability isn’t enough, and having a long-term memory about decisions that are unrecoverable by looking at the code only becomes essential.
If you already use it with your team/company, congrats, you already have a great knowledge base for your agents.
But if not, better late than never. Explain the concept to your team, your team lead, your peers, or anyone else who would need to be convinced, and propose a trial.
On top of that, writing ADR has never been so easy thanks to LLMs. They can write an ADR for you based on a conversation, or even a transcribed note, and they will reuse those ADRs in the future.
The loop is closed 😅